Success-Plan Services
Success-Plan Services
3 min read
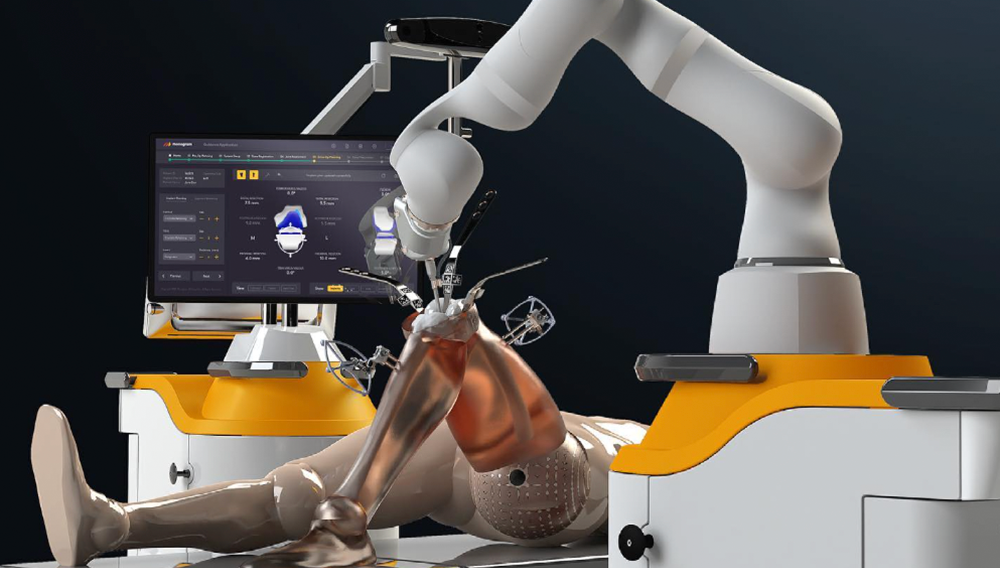
Integrating Video Streaming with Real-Time Data for Surgical Use Cases and Beyond
**Please note that with the April 2024 release of Connext Professional 7.3 LTS, the functionalities formerly comprising Connext Secure are now...
Read more ⇢